Методы сжатия речевых сигналов
Основные объемы передаваемой в системах связи информации приходится на речь – это и проводная телефония, и системы сотовой и спутниковой связи, и т.д. Поэтому эффективному кодированию, или сжатию речи, в системах связи уделяется исключительное внимание.
Рассмотрим основные свойства речевого сигнала как объекта экономного кодирования и передачи по каналам связи и попытаемся пояснить, на каких свойствах сигнала основывается возможность его сжатия.
Следует отметить, что уровень низкочастотных (то есть медленных по времени) составляющих в спектре речевого сигнала значительно выше уровня высокочастотных (быстрых) составляющих. Эта существенная неравномерность спектра является одним из факторов сжимаемости таких сигналов.
Второй особенностью речевых сигналов является неравномерность распределения вероятностей (плотности вероятности) мгновенных значений сигнала. Малые уровни сигнала значительно более вероятны, чем большие. Особенно это заметно на фрагментах большой длительности с невысокой активностью речи. Этот фактор также обеспечивает возможность экономного кодирования – более вероятные значения могут кодироваться короткими кодами, менее вероятные – длинными.
Еще одна особенность речевых сигналов – их существенная нестационарность во времени: свойства и параметры сигнала на различных участках значительно различаются. При этом размер интервала стационарности составляет порядка нескольких десятков миллисекунд. Это свойство сигнала значительно затрудняет его экономное кодирование и заставляет делать системы сжатия адаптивными, то есть подстраивающимися под значения параметров сигнала на каждом из участков.
Простейшими кодерами/декодерами речи являются кодеры/декодеры формы сигнала. Они могут использоваться для кодирования любых, в том числе и неречевых, сигналов.
Простейшим способом кодирования формы сигнала является импульсно-кодовая модуляция – ИКМ, при использовании которой производятся просто дискретизация и равномерное квантование входного сигнала, а также преобразование полученного результата в равномерный двоичный код.
Для речевых сигналов со стандартной для передачи речи полосой 0,3 – 3,5 кГц обычно используют частоту дискретизации Fдискр³2Fmax= 8 кГц. Экспериментально показано, что при равномерном квантовании для получения практически идеального качества речи нужно квантовать сигнал не менее чем на ± 2000 уровней
Используя неравномерное квантование (более точное для малых уровней сигнала и более грубое для больших его уровней), можно достичь того же качества восстановления речевого сигнала, но при гораздо меньшем числе уровней квантования – порядка 128.
С учетом статистических свойств речевого сигнала, а также нелинейных свойств слуха, гораздо лучше различающего слабые звуки, оптимальной является логарифмическаяшкалаквантования, которая и была принята в качестве стандарта в середине 60-х годов и сегодня повсеместно используется.
Следующим приемом, позволяющим эффективность кодирования, может быть попытка предсказать значение текущего отсчета сигнала по нескольким предыдущим его значениям, и далее, кодирование уже не самого отсчета, а ошибки его предсказания – разницы между истинным значением текущего отсчета и его предсказанным значением. Если точность предсказания достаточно высока, то ошибка предсказания очередного отсчета будет значительно меньше величины самого отсчета и для ее кодирования понадобится гораздо меньшее число бит. Таким образом, чем более предсказуемым будет поведение кодируемого сигнала, тем более эффективным будет его сжатие.
Эффективность ДИКМ может быть повышена, если предсказание и квантование сигнала будет выполняться не на основе некоторых усредненных его характеристик, а с учетом их текущего значения и изменения во времени, то есть адаптивно. Так, если скорость изменения сигнала стала большей, можно увеличить шаг квантования, и, наоборот, если сигнал стал изменяться медленнее, величину шага квантования можно уменьшить. При этом ошибка предсказания уменьшится и, следовательно, будет кодироваться меньшим числом бит на отсчет. Такой способ кодирования называется адаптивной ДИКМ, или АДИКМ (ADPCM). Сегодня он стандартизован и широко используется при сжатии речи в междугородных цифровых системах связи, в системе микросотовой связи DECT, в цифровых переносных телефонах и т.д.
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Какие существуют стандарты сжатия речи
Актуальность темы. В сфере телекоммуникаций всегда стоял вопрос о том, как обеспечить связь как можно большее количество абонентов, по как можно меньшему количеству каналов. Для решения этого вопроса научные сообщества вкладывают гигантское количество денег в разработку компрессии речевых сигналов, что приводит к снижению информационной емкости передаваемых по каналам связи речевых сообщений и удешевлению услуг средств связи. Кроме этого компрессия речевых сигналов востребована и в военной области и других ведомствах для обеспечения закрытой информации. Так же следует обратить внимание на быстрый рост компьютерных сетей. При улучшении качества вокодерной речи при скоростях менее 4 кбит/с становиться возможным коммуникация по компьютерным сетям.
Современные достижения в области создания высокопроизводительных вычислительных элементов, таких как микроконтролеры цифровой обработки сигналов позволяют практически неограниченно совершенствовать методы и алгоритмы цифровой обработки речевого сигнала.
Объект и предмет исследования. Исследуются алгоритмы кодирования речевой информации на предмет их эффективности и рационального использования в зависимости от конкретной системы передачи данных.
Научная новизна полученных результатов состоит в разработке математической модели алгоритма и изучение на базе её поведения и свойств реальной системы в зависимости от характеристик передаваемых данных, поведено исследование влияния ошибок в системе на качество кодирования, исследовано влияние ошибок в канале передачи данных на выходной сигнал декодера.
1. Аналитический обзор
Краткая характеристика механизма речеобразования
В составе спектра речевого сигнала можно отметить, что уровень низкочастотных (т.е. медленных по времени) составляющих значительно выше уровня высокочастотных (быстрых) составляющих. Эта существенная неравномерность спектра, кстати, является одним из факторов сжимаемости таких сигналов.
Голосовой тракт начинается от голосовых связок и заканчивается губами и в среднем имеет длину порядка 15-17 сантиметров. Голосовой тракт в силу своих резонансных свойств вносит в формируемый сигнал набор характерных для каждого человека частотных составляющих, называемых формантами и придающих голосу тембровую окраску.
Некоторые звуки в чистом виде не подходят ни под один из описанных выше классов, но могут рассматриваться как их смесь. Таким образом, процесс речеобразования можно рассматривать как фильтрацию речеобразующим трактом с изменяющимися во времени параметрами сигналов возбуждения, также с изменяющимися характеристиками. (рис.1.1)
При этом, несмотря на исключительное разнообразие генерируемых речевых сигналов, форма и параметры голосового тракта, а также способы и параметры возбуждения достаточно однообразны и изменяются сравнительно медленно. Речевой сигнал обладает высокой степенью кратковременной и долговременной предсказуемости из-за периодичности вибраций голосовых связок и резонансных свойств голосового тракта. Большинство кодеров/декодеров речи и используют эту предсказуемость, а также низкую скорость изменения параметров модели системы речеобразования для уменьшения скорости кода.
Существующие решения
Кодирование формы сигнала
Кодирование формы сигнала позволяет достигнуть компрессии речевого сигнала, с приемлемым (коммерческим) качеством, до 24 Кбит/с. Данное сжатие достигается за счет применения адаптивной дифференциальной импульсно-кодовой модуляции (стандарт G.271 или G.279).
Принцип кодирования заключается в следующем: входной сигнал А- или μ-закона преобразуется в сигнал линейной ИКМ, далее из этого сигнала вычитается оценка сигнала, затем полученная разность поступает на вход адаптивного квантователя, где вычисляется выходной сигнал кодера с величиной кодового слова 2,3,4 или 5 бит, в зависимости от настройки кодера, в инверсном адаптивном квантователе происходит обратная операция, т.е. вычисляется квантованный разностный сигнал, представляющий собой восстановленную разность входного сигнала и оценки сигнала, затем адаптивным линейным предсказателем и вычисленным значением восстановленного сигнала на основе некоторого количества раннее пришедших отсчетов квантованного разностного сигнала вычисляется следующий отсчет оценки сигнала, который является предсказанным значением следующего отсчета входного сигнала.
Далее процесс повторяется по вышеописанному алгоритму. Структурная схема декодера АДИКМ представлена на рисунке 1.3.
Снижение скорости происходит благодаря тому, что в канал передается не сам отсчет, а разность между истинным и предсказанным значением, длина полученного таким образом кодового слова меньше чем при обычной ИКМ.
Поскольку каждый из частотных поддиапазонов имеет более узкую полосу (все поддиапазоны в сумме дают полосу исходного сигнала), то и частота дискретизации в каждом поддиапазоне также будет меньше. В результате суммарная скорость всех кодов будет по крайней мере не больше, чем скорость кода для исходного сигнала. Однако у такой техники есть определенные преимущества. Дело в том, что субъективная чувствительность слуха к сигналам и их искажениям различна на разных частотах. Она максимальна на частотах 1-1,5 кГц и уменьшается на более низких и более высоких частотах. Таким образом, если в диапазоне более высокой чувствительности слуха квантовать сигнал более точно, а в диапазонах низкой чувствительности более грубо, то можно получить выигрыш в результирующей скорости кода. При использовании технологии кодирования поддиапазонов получено хорошее качество кодируемой речи при скорости кода 16-32 кбит/с. Кодер получается несколько более сложным, чем при простой АДИКМ, однако гораздо проще, нежели для других эффективных способов сжатия речи.
Близким к кодированию поддиапазонов является метод сжатия, основанный на применении к сигналу линейных преобразований, к примеру, дискретного косинусного или синусного преобразования. Для кодирования речи используется так называемая технология АТС (Adaptive Transform Coding), при которой сигнал разбивается на блоки, к каждому блоку применяется дискретное косинусное преобразование и полученные коэффициенты адаптивно, в соответствии с характером спектра сигнала, квантуются. Чем более значимыми являются коэффициенты преобразования, тем большим числом бит они кодируются. Достигаемые при таком кодировании скорости кодов составляют 12-16 кбит/с при вполне удовлетворительном качестве сигнала. Широкого распространения для сжатия речи этот метод не получил, поскольку известны гораздо более эффективные и простые в исполнении методы кодирования.
Следующим большим классом кодеров речевых сигналов являются кодеры источника.
Кодирование параметров источника
Кодирование параметров источника сигнала осуществляется путем вычисления параметров, описывающих передаточную функцию речевого тракта человека. К примеру, такими параметрами являются коэффициенты линейного предсказания (модель авторегрессии). В данной категории кодирования параметров источника сигнала достигнут предел в 2400 бит/с (стандарт FS1015).
Канальные вокодеры
Это наиболее древний тип вокодера, предложенный еще в 1939 году. Этот вокодер использует слабую чувствительность слуха человека к незначительным фазовым (временным) сдвигам сигнала, поскольку органы слуха человека не реагируют на фазовые соотношения.

Рис. 1.4. Канальный вокодер
Канальный вокодер может быть реализован как в цифровой, так и в аналоговой форме и обеспечивает достаточно разборчивую речь при скорости кода на его выходе порядка 4,8 кбит/с.
Декодер (рис. 1.5), получив информацию, вырабатываемую кодером, обрабатывает ее в обратном порядке, синтезируя на своем выходе речевой сигнал, в какой-то мере похожий на исходный.

Рис. 1.5. Декодер канального вокодера
Учитывая простоту модели, трудно ожидать от вокодерного сжатия хорошего качества восстановленной речи. Действительно, канальные вокодеры используются в основном только там, где главным образом необходимы разборчивость и высокая степень сжатия: в военной связи, авиации, космической связи.
Хотя данный вокодер не обладает высоким качеством, но он является основоположником кодирования источника. Теперь рассмотрим еще один вокодер, который широко используется в сотовой связи GSM.
Кодеры с регулярным импульсным возбуждением
Кодер Regular Pulse Excited, или RPE-кодек, использует в качестве сигнала возбуждения фиксированный набор коротких импульсов. Однако в этом кодеке импульсы расположены регулярно на одинаковых расстояниях друг от друга, и кодеру необходимо определить лишь положение первого импульса и амплитуды всех импульсов. Таким образом, декодеру нужно передавать меньше информации о положении импульсов, следовательно, в сигнал возбуждения можно включить их большее количество и тем самым улучшить приближение синтезированного сигнала к оригиналу. К примеру, если при скорости кода 10 кбит/с в МРЕ-кодеке используется четырехимпульсный сигнал возбуждения, то в RPE-кодеке можно использовать уже десятиимпульсный сигнал. При этом существенно повышается качество речи.
Кодирование элементов речи и кодирование лингвистических элементов
Кодирование элементов речи и кодирование лингвистических элементов на данный момент является обширной и практически не изученной категорией методов компрессии речи. Данное кодирование осуществляется методами распознания и синтеза речи. Часто кодирование происходит с помощью скрытых марковских моделей (HMM) и нейронных сетей. К сожалению, хотя и существует огромное количество разработок, данный вид кодирования пока не обладает достаточной точностью и устойчивостью для внедрения в телекоммуникационные услуги.
2. Задачи работы и ожидаемые результаты
Задачей квалификационной работы является развитие категории кодеков кодирования элементов речи, используя нейросетевые технологии. Вследствие чего основная задача работы распадается на две под задачи: распознавание элементов речи в речевом сигнале на передающей стороне и синтез из полученных элементов речевого сигнала на приемной стороне. Задача синтеза в принципе уже решена и имеется большое количество разработок обладающих хорошим качеством синтезированной речи. Одно из таких решений, освещенной в работе [2], является система Net-Talk, которая может преобразовывать английский текст в речевой сигнал. А вот задача распознавания элементов речи, представляется сложной до сегодняшних дней.
Основная проблема распознавания элементов речи заключается в построении как можно более точных акустических моделей. Акустические модели и акустический анализ, в общем, представляет собой модель человеческого уха и применение, хорошо зарекомендовавших себя, нейронных сетей обуславливается хотя бы тем, что они близки по природе к поставленной проблеме. Так же применение нейронных сетей обусловлены следующими факторами:
Существует много различных моделей сетей, с различной архитектурой, обучающей процедурой, но все они основаны на некоторых общих принципах. Искусственная нейронная сеть состоит из большого количества простых элементов (т.н. модулей, узлов, или нейронов), которые влияют на поведенение друг друга через сеть весов. Каждый элемент просто вычисляет нелинейную взвешенную сумму входов, и передает результат по его уходящим связям к другим элементам. Обучение заключается в подборе весов при представлении сети известных образцов входов и выходов.
Много биологических подробностей игнорируется в упрощенных моделях. Например, биологические нейроны генерируют последовательности импульсов, а не устойчивое значение (на данный момент существуют разработки симулирующие данное свойство, но увеличивается сложность реализации); также существует несколько различных типов биологических нейронов; их физическая геометрия может затронуть вычислительные возможности; на их поведение влияют гормоны и другие химикалии. Такие подробности могут в конечном итоге понадобится для модели мозга, но пока упрощенная модель имеет вычислительную мощность для решения проблем, для которых нужны преимущества нейронных сетей.
На данный момент рассмотрены основные методы распознания фонем такие как, скрытые марковские модели (HMM), нейронные сети и их комбинации. Данные методы требую предварительного преобразования речевого сигнала с целью получения вектора свойств характеризующего данный момент времени речевого сигнала. Элементы вектора составляются из коэффициентов преобразования таких как, преобразование Фурье, вейвлет преобразование или коэффициенты линейного предсказания. Недостаток данной методики в том, что вид и количество коэффициентов преобразования задаются заранее и могут нести продублированную или ненужную информацию о речевом сигнала. На основе работы [3], найденно свойство нейрона находить корреляцию между сигналом и весовой функцией. На основе данного свойства была предложена следующая структура системы распознания фонем в речевом сигнале:
Входной сигнал речи поступает на вход линии задержки (ЛЗ), которая формирует входной вектор нейронной сети, представляющей собой отрезок сигнала входящего в анализирующий кадр. С линии задержки сигнал поступает на корреляционный слой (КС) нейронов, количество нейронов зависит от того, сколько необходимо сформировать коррелятов. С корреляционного слоя сигнал поступает на вход анализирующей сети (АС) состоящей из двух слоев нейронов. Во втором слое анализирующей сети каждый нейрон соответствует признаку отдельной фонемы. Выходами анализирующего слоя являются сигналы показывающие какая фонема в данный момент возможно находится во входном сигнале. Данная система обладает тем преимуществом, что при обучении ее в корреляционном слое будет формироваться группа коррелятов речевого сигнала, то есть автоматически формируется входной вектор нейронной сети с необходимыми свойствами характеризующие речевой сигнал. Количество свойств зависит от количества нейронов входящих в данный слой. В анализирующем слое будет формироваться метод анализа данных коррелятов и сопоставление их с признаками фонем. Хотелось бы заметить, то что в рабочем режиме скорость работы данной системы не будет превышать скорости работы системы с анализатором на основе преобразования Фурье или вейвлет.
Заключение
Был произведен анализ основных кодеков речевого сигнала. В ходе анализа было выяснено, что на сегодняшний день достигнут предел сжатия в 2400 bits/s, хотя экспериментально установлено [4], что если речь передавать текстом, то скорость кода будет равна 50 bit/s, что в 48 раз больше. Это объясняется тем, что все методы компрессии основаны на лобовой аппроксимизации речевого сигнала без учета его акустико-информационной структуры [5]. На данный момент сформирована концепция нейронной сети преобразующей речевой сигнал в поток фонем. Данная сеть, при обучении, должна сформировать набор коррелятов и правил, учитывающих структуру речевого сигнала. Для обучения данной сети необходимо построить методику ее обучения и сформировать обучающие шаблоны. В конечном счете планируется провести исследование на правильность распознавания и устойчивость к помехам.
Окончание работы и получение результатов планируется к началу 2008 года.
ОПИСАНИЕ СУЩЕСТВУЮЩИХ МЕТОДОВ СЖАТИЯ РЕЧИ
Дальнейшее снижение скорости передачи возможно при использовании схем анализ-синтез речи, учитывающих особенности цифровой модели формирования речи. Применяют два варианта таких схем – без обратной связи и с обратной связью.
На рисунке 2.1 (а) приведена схема сжатия речи без обратной связи, основанная на анализе по методу линейного предсказания и синтезе речевого сигнала. Здесь речевой сигнал s[n] разбивается на сегменты длительностью 20-39 мс. На каждом из сегментов с помощью устройства оценивания (УО) определяются коэффициенты линейного инверсного фильтра-анализа Ф1 десятого порядка. Кроме этого, на этапе сжатия с помощью выделения основного тона (ОТ) и анализатора тон-шум (Т-Ш) определяются соответствующие параметры функции возбуждения. В кодере выполняется кодирование коэффициентов фильтра и параметров функции возбуждения, которые затем передаются по каналу связи или сохраняются в памяти.
В системе, изображенной на рисунке 2.1 б), параметры возбуждения (частота основного тона, признак тон/шум, форма сигнала возбуждения) формируются без учета их влияния на качество синтезированной речи, поэтому восстановленная речь как механическая и не обеспечивает узнаваемости голоса.

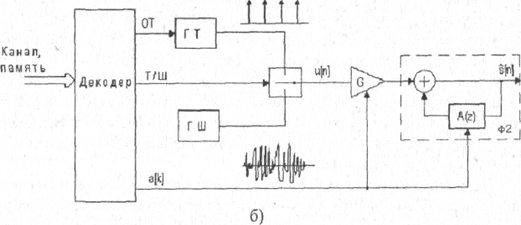
Для повышения натуральности речи используется схема анализа-синтеза с обратной связью (рисунок 2.2). В этой схеме возбуждающая последовательность формируется путем минимизации ошибки восстановления речевого сигнала, т.е. разности между исходным речевым сигналом s [ n ] и восстановленным сигналом S [ n ]. Восстановленный речевой сигнал формируется с помощью фильтров Ф1 и Ф2, на вход которых подается сигнал с выхода генератора функции возбуждения (ФВ). Фильтр Ф1 учитывает квазипериодические свойства вокализованных участков речи, а фильтр Ф2 моделирует формантную структуру речи. Инверсный фильтр, соответствующий фильтру Ф1, является фильтром долговременного предсказания, а инверсный фильтр, соответствующий фильтру Ф2, называется фильтром кратковременного предсказания.
Фильтр долговременного предсказания описывается передаточной функцией
где AL ( z )- az ^- t и t — задержка, соответствующая периоду основного тона, равная 20-150 интервалам дискретизации. Если на вход фильтра долговременного предсказания подать сигнал ошибки кратковременного предсказания dK [ n ], то в соответствии с (2.1) ошибка долговременного предсказания d Д <[ n ] будет равна:
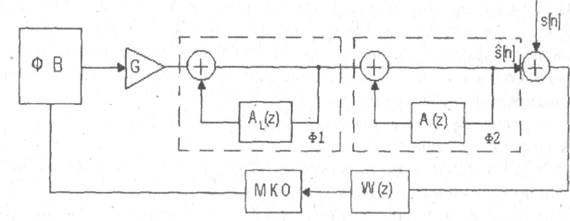
Данная ошибка по своим свойствам близка к белому шуму с нормальным законом распределения. Это упрощает формирование сигнала возбуждения, так как при синтезе последовательности S [ n ] ошибка долговременного предсказания выступает в роли сигнала возбуждения.
Фильтр с передаточной функцией W(z) (рисунок 2.2) позволяет учесть особенности слухового восприятия человека. Для человека шум наименее заметен в частотных полосах сигнала с большими значениями спектральной плотности. Этот эффект называют маскировкой. Фильтр W(z) учитывает эффект маскировки и придает ошибке восстановления различный вес в разных частотных диапазонах. Вес выбирается так, чтобы ошибка восстановления маскировалась в полосах речевого сигнала с высокой энергией.
Принцип работы схемы, изображенной на рисунке 2.2, состоит в выборе функции возбуждения (ФВ), минимизирующей квадрат ошибки (МКО) восстановления.
В настоящее время применяется несколько стандартов, основывающихся на рассмотренной схеме сжатия:
1) RPE-LPC со скоростью передачи 13 Кбит/с используется в качестве стандарта мобильной связи в Европейских странах;
2)CELP со скоростью передачи 4,8 Кбит/с. Одобрен в США федеральным стандартом FS-1016. Используется в системах скрытой телефонной связи;
3)VCELP со скоростью передачи 7,95 Кбит/с (vector sum excited linearprediction). Используется в цифровых сотовых системах в Северной Америке. VCELP со скоростью передачи 6,7 Кбит/с принят в качестве стандарта в сотовых сетях Японии;
4)LD-CELP (low-delay CELP) одобрен стандартом МККТТ G.728. Вданном стандарте достигается небольшая задержка примерно 0,625 мс(обычно методы CELP имеют задержку 40-60 мс), используются короткие векторы возбуждения и не применяется фильтр долговременного предсказания с передаточной функцией АL(z).
Необходимо отметить, что рассмотренные методы сжатия речи, использующие линейное предсказание с кодовым возбуждением, хорошо приспособлены для работы с речевыми сигналами в среде без шумов. В случае шумового воздействия на речевые сигналы синтезированная речь имеет плохое качество. Поэтому в настоящее время разрабатывается ряд методов линейного предсказания с кодовым возбуждением для использования в шумовой обстановке (ACELP, CS-CELP).
На рисунке 2.3,а изображена обобщенная схема сжатия речевого сигнала с помощью алгоритмов векторного квантования.
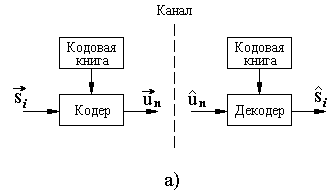 | 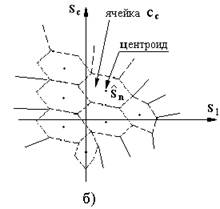 |
Рисунок 2.3 – Векторное квантование
Входной вектор si представляет собой вектор признаков речевого сигнала (например, спектральных),
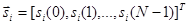 .
.
Кодер отображает входной вектор 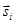 в выходной символ un, n = 1, 2, …, L с помощью кодовой книги. Кодовая книга содержит L векторов
в выходной символ un, n = 1, 2, …, L с помощью кодовой книги. Кодовая книга содержит L векторов
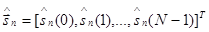 , n = 1, 2, …, L.
, n = 1, 2, …, L.
Предположим, что канал не имеет шумов, т.е. 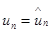 .
.
Векторный квантователь функционирует следующим образом. Входной вектор сравнивается с каждым вектором из кодовой книги. В результате из кодовой книги выбирается вектор  , ближайший к вектору , и в канал передается символ un, представляющий адрес найденного кодового вектора. На приемной стороне с помощью полученного адреса un восстанавливается вектор признаков речевого сигнала
, ближайший к вектору , и в канал передается символ un, представляющий адрес найденного кодового вектора. На приемной стороне с помощью полученного адреса un восстанавливается вектор признаков речевого сигнала  , на основе которого синтезируется речевой процесс. В такой интерпретации векторное квантование, по сути, является распознаванием образов, где вектор представляет собой входной образ, кодовая книга соответствует базе эталонов.
, на основе которого синтезируется речевой процесс. В такой интерпретации векторное квантование, по сути, является распознаванием образов, где вектор представляет собой входной образ, кодовая книга соответствует базе эталонов.
В качестве меры расстояния между входными векторами и векторами из кодовой книги обычно используется сумма квадратов отклонений si(k) и 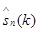 :
:
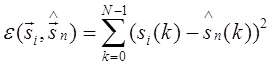 (2.3)
(2.3)
В простейшем случае, если вектор представляет собой блок отсчетов речевого сигнала, рассмотренная схема квантования является обобщением импульсной кодовой модуляции (ИКМ), и называется векторной ИКМ. В векторной ИКМ (ВИКМ) число битов, приходящихся один отсчет речевого сигнала определяется по формуле
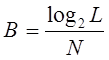 (2.4)
(2.4)
ВИКМ имеет преимущество перед различными видами ИКМ [ 1 ], если 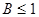 .
.
Процесс проектирования кодовой книги, который связан с обучением, может быть реализован двумя способами. В первом случае кодовая книга разрабатывается на основе алгоритма К-средних. Рекомендуется, чтобы обучающая выборка содержала по 40 примеров векторов признаков для каждого кодового вектора. Вычислительную сложность разработки кодовой книги можно снизить, если определенным образом структурировать кодовую книгу. Действительно, так как в процессе построения кодовой книги выполняется поиск среди L векторов-эталонов, то упорядочение книги может привести к сокращению времени поиска. Для ускорения поиска часто применяют бинарные деревья [2]. Сложность вычислений можно уменьшить, если в кодовой книге отдельно хранить нормализованные векторы 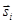 и масштабный коэффициент G (коэффициент усиления).
и масштабный коэффициент G (коэффициент усиления).
Во втором случае кодовая книга создается с помощью алгоритма обучения, в соответствии с которым положение центроидов на каждом шаге уточняется по рекуррентной формуле
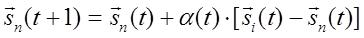 , (2.5)
, (2.5)
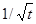 .Формула уточняет положение только того центроида, для которого входной вектор
.Формула уточняет положение только того центроида, для которого входной вектор  оказался ближайшим.
оказался ближайшим.
Выражение (2.5) соответствует правилу обучения состязательных нейронных сетей, в частности, правилу Кохонена. Подробнее см. в [2].
Существует различные схемы сжатия речи c помощью алгоритмов векторного квантования. Большинство из них основано на схеме “анализ-синтез”. Применяют два варианта таких схем – без обратной связи и с обратной связью [1]. В основе каждой из схем лежит модель синтеза речи на основе коэффициентов линейного предсказания [1]. В соответствии с этой моделью речь может быть получена путем подачи специальным образом подобранного возбуждающего сигнала на вход линейного фильтра, который моделирует резонансные частоты голосового тракта. Передаточная функция фильтра описывается уравнением
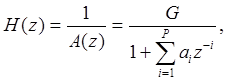 (2.6)
(2.6)
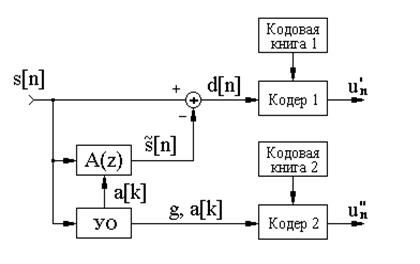
Возможная структурная схема системы низкоскоростного кодирования речи с помощью алгоритмов векторного квантования изображена на рисунке 2.2.
 |
 |
Рисунок 2.4 – Низкоскоростное кодирование речи
Процедура кодирования речи сводится к следующему:
— оцифрованный речевой сигнал s[n] нарезается на сегменты длительностью 20 мс (при fg=8 КГц в каждом сегменте будет по 160 выборок);
— для каждого сегмента вычисляются с помощью устройства оценивания (УО) параметры фильтра линейного предсказания и определяется ошибка предсказания d[n], соответствующая функции возбуждения;
— функция возбуждения и параметры фильтра линейного предсказания кодируются с помощью отдельных векторных квантователей и передаются в канал.
Процедура декодирования заключается в пропускании восстановленного сигнала возбуждения через синтезирующий фильтр (2.4), параметры которого переданы одновременно с функцией возбуждения.
Приведенное описание процессов кодирования и декодирования речи не является исчерпывающим, оно объясняет лишь принцип действия кодера. Практические схемы намного сложнее, и это связано в основном со следующими двумя моментами.
Во-первых, на рисунке 2.2 изображена схема без обратной связи. Лучшего качества синтезируемой речи можно добиться в схемах с обратной связью [1]. Однако такие схемы сложнее.
Во-вторых, описанная выше схема, использует кратковременное предсказание и не обеспечивает в достаточной степени устранения избыточной речи. Поэтому в дополнение к кратковременному предсказанию используется еще и долговременное предсказание [1]. Выходной сигнал фильтра кратковременного предсказания используется для оценивания параметров фильтра долговременного предсказания – задержки τ и коэффициента предсказания a:

При оценке качества кодирования и сопоставлении различных кодеров оцениваются разборчивость речи и качество синтеза речи (качество звучания). Для оценки разборчивости речи используется метод ДРТ (диагностический рифмованный текст). В этом методе подбираются пары близких по звучанию слов, отличающиеся отдельными согласными (“кол-гол-пол”), которые многократно произносятся рядом дикторов, и по результатам испытаний оценивается доля искажений [3,4].
Для оценки качества звучания используется критерий ДМП (диагностическая мера приемлемости) [4]. Испытания заключаются в чтении несколькими дикторами, мужчинами и женщинами, ряда специально подобранных фраз, которые прослушиваются на выходе тракта связи рядом экспертов-слушателей, выставляющих свои оценки по 5-балльной шкале. Результатом является средняя оценка мнений (MOS).
Обратим внимание на следующий факт. Если кодовая книга создается на обучающих данных, принадлежащих только одному диктору, тоне следует ожидать, что она будет обеспечивать хорошее качество звучания для другого диктора. Соответственно, кодовая книга, полученная в лабораторных условиях, не обеспечит того же качества звучания при записи речи в шумовой обстановке, например, в салоне автомобиля. Для построения дикторо-независимой системы необходимо проектировать кодовую книгу на речевых сигналах различных дикторов.

Организация стока поверхностных вод: Наибольшее количество влаги на земном шаре испаряется с поверхности морей и океанов (88‰).



Поперечные профили набережных и береговой полосы: На городских территориях берегоукрепление проектируют с учетом технических и экономических требований, но особое значение придают эстетическим.


