Сильные и слабые стороны NoSQL
Сильные и слабые стороны NoSQL
SQL (Structured Query Language) — универсальный язык запросов, который используется всеми реляционными системами.
NoSQL имеют собственный API для взаимодействия.
Преимущества РСУБД — соответствия базы данных требованиям ACID, целостность данных, структурированность.
Преимущества NoSQL — скорость обработки данных, масштабируемость, распределенность систем.
Сильные стороны
Репликация — это копирование обновленных данных на другие сервера. Это позволяет добиться большей отказоустойчивости и масштабируемости системы.
Тип master-slave — это один мастер-сервер и несколько дочерних серверов. Запись может производиться только на мастер-сервер, который передает изменения на дочерние машины. Этот тип репликации даёт хорошую масштабируемость на чтение, но не на запись, так как запись идет только на мастер-сервер. Этот тип репликации имеет свой минус — в случае неисправности мастер-сервера нужно выбирать(автоматически или вручную) новый мастер-сервер.
Второй тип — peer-to-peer — все узлы равны в возможности обслуживать запросы на чтение и запись. Информация о обновлении данных передается от сервера к серверу.
Слабые стороны
У большинства компаний просто нет таких объемов данных и других специфических условий работы, в которых NoSQL решения были бы выгодны в качестве основной базы данных. NoSQL хранилища показывают себя с очень хорошей стороны в симбиозе с реляционными базами данных. Например, в системах, где основной объем информации хранит SQL, а за кэш отвечает NoSQL.
Нереляционным системам всё ещё не хватает универсальности, надежности, целостности и предсказуем
Что такое NoSQL
Это нереляционные базы данных.
Когда мы разбирали виды баз данных, то сказали, что они бывают реляционные и все остальные. Реляционные — самые распространённые, вы встретите их под капотом большинства сайтов, чаще всего они управляются через систему MySQL.
Но одно решение не может подходить всем и всегда. Сегодня поговорим обо всех остальных вариантах, которые собраны под единым большим термином NoSQL — это общее название для нереляционных баз данных.
Способ организации данных
В SQL-базах всё просто: есть, условно говоря, таблицы, и есть связи между ними. Все данные хранятся в этих таблицах.
В NoSQL-базах всё иначе — там может не быть таблиц, а вместо них — свои модели данных. Каждая из них подходит под свои задачи, универсальной нет. Вот основные модели:
Ключ-значение
У каждой записи есть название поля и его значение. Например:
name: ‘Миша’
today: ‘9/09/2020’
president: ‘Путин’
writer: ‘Пушкин’
pogoda: ‘ну такая’
Первая часть — это ключ, вторая часть — значение. И можно подсыпать сколько хочешь новых ключей.
Это полезно, например, для словарей или механизмов автозамены: «Если встретилось такое слово — замени на вот такое».
Колонки
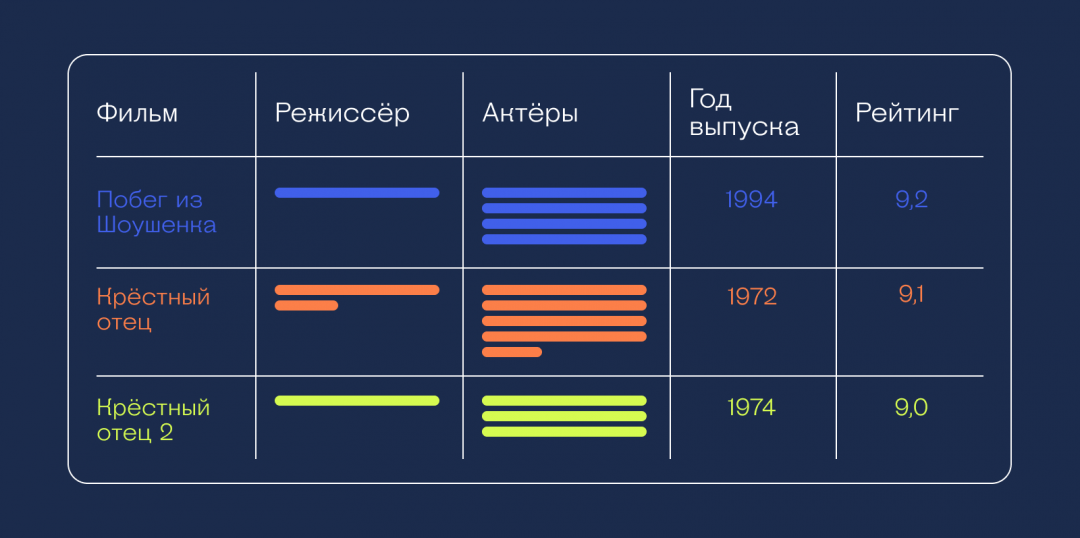
Представьте себе одну огромную таблицу, в которой хранятся все данные в базе. Отличие от традиционной схемы в том, что в SQL-базах работа идёт со строками, а здесь — с колонками. Например, если в такую базу занести список из 250 лучших фильмов с названиями, актёрами и режиссёрами, то все названия можно получить с помощью только одного запроса и одного обращения к базе. В случае с SQL таких обращений к базе было бы 250 — по одному на каждую строку.
Графы
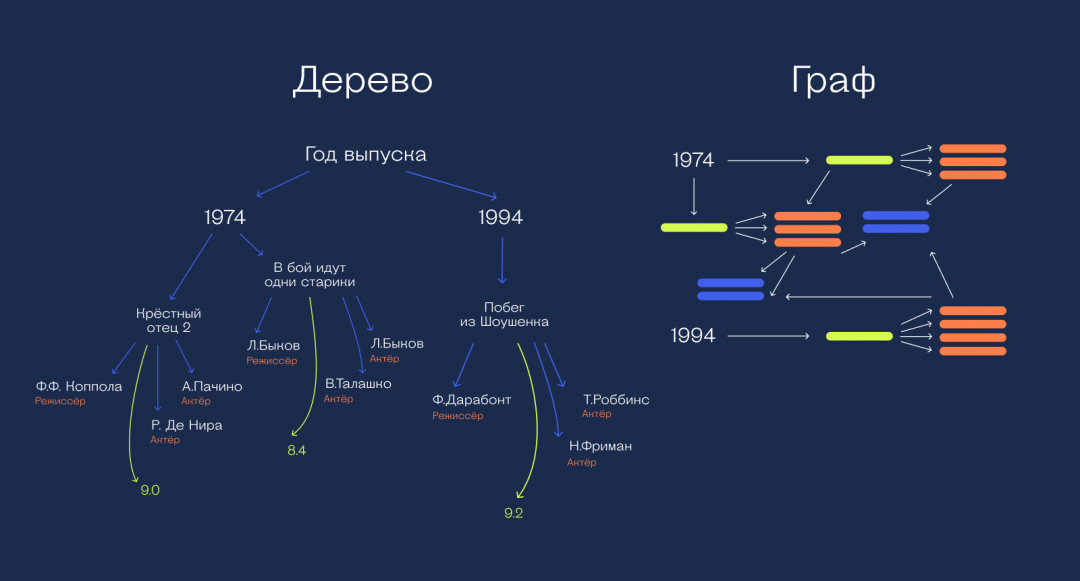
Если ваши данные можно представить в виде графа или дерева, то вам подойдёт и база данных с таким же подходом к хранению и поиску.
Дерево — это когда данные хранятся по системе «родитель — отпрыски». Есть некий родительский кусок данных, у него есть связанные с ним отпрыски. У тех тоже могут быть свои отпрыски и так далее. Каждая единица данных может быть чьим-то отпрыском (но только кого-то одного) и иметь сколько-то собственных отпрысков.
В деревьях удобно хранить данные, например, для поисковых алгоритмов. В «деревьях» также хранятся файлы на вашем компьютере: есть корневой каталог, в нём вложенные папки, в них ещё папки, в них файлы. Один и тот же файл не может храниться одновременно в двух местах.
Графы — это когда данные связаны вообще как хочешь. Один кусок данных может быть связан с любыми другими в любом количестве и в любом направлении. Дерево — частный случай графа.
❤️ Про деревья мы недавно писали: что такое Trie и как работает бустинг
Документы
Вот это космос, смотрите.
Если мы храним данные в таблице, у нас есть столбцы и строки. И если у нас про кого-то есть данные, а про другого нет, — где-то в таблице будут пропуски. А если в таблице нет нужного столбца, а нам нужно положить в неё новый тип данных, нам придётся создавать новый столбец, и он для всех будет пустым:
| Имя | Возраст | Город | Роль |
| Миша | 35 | Брянск | Редактор |
| Женя | Москва | Директор | |
| Родион | Ульяновск |
Реляционная БД заставляет нас заранее придумывать, как будет работать база данных; какие там будут поля; какие допустимы типы данных. Например, в таблицу выше уже не добавишь информацию о том, что Родион носит бороду — точнее, добавить-то её можно, но тогда у нас появится куча пустых ячеек. А если этих столбцов нужно добавлять много? Это крайне нерационально.
Теперь представьте, что есть механизм, который позволяет хранить эти данные в более свободном формате. Например:
name: Миша
age: 35
city: Брянск
job: Редактор
stickerpack: Доктор Хаус
Каждая из этих записей (про Мишу, Женю и Родиона) — это три отдельных документа. И база данных настолько умна, что может при необходимости распознать, что там где лежит. Если мы запросим у нее Boroda, то она прошерстит все документы и поищет там разметку со словом «Борода». В первых двух документах этой разметки не будет, а в третьем — будет. Именно этот документ нам база данных и вернёт.
Работа с SQL-запросами
Уже по названию видно, что NoSQL не поддерживает SQL-запросы. Это значит, что у каждой такой базы своя методика работы с данными и общего стандарта нет. Не получится выучить операции в Redis, который работает по принципу «ключ-значение» и быстро освоить MongoDB, где всё основано на документах.
Некоторые NoSQL-базы пытаются поддерживать что-то из SQL, но на практике это работает плохо.
Скорость и масштабируемость
Чтобы реляционная база данных могла работать с большим объёмом данных, нужно поставить железо помощнее или добавить несколько копий такой базы, чтобы можно было быстрее читать из неё.
В NoSQL-подходе базу легко разделить между несколькими компьютерами, связанными по сети. Чем больше компьютеров и чем быстрее сеть — тем больше база и скорость работы. Получается, что железо можно оставить тем же, и просто увеличить количество узлов в базе.
Надёжность и безопасность
Реляционная база данных надёжна как скала, в ней не может случиться ничего плохого, потому что она сама за этим следит. А если такое случается, то всегда можно вернуться на шаг назад и восстановить все данные без потерь. За это приходится платить скоростью работы.
NoSQL-базы относятся к этому иначе: они предлагают максимальную скорость работы, а решение всех конфликтов зависит от программиста. Если одну и ту же ячейку хотят изменить два пользователя, а программист этого не предусмотрел, то кто быстрее записал — тот и прав. Поэтому в таких базах нужно отдельно следить за надёжностью и решением конфликтов.
Применение
Обычные SQL-базы отлично подходят для типовых задач, где надёжность и предсказуемость важнее скорости. Например, для записей о пациентах, перемещениях товаров со склада или школьных оценок.
Но если вам нужна скорость, масштаб и большая мощность — посмотрите на NoSQL. Единственный минус — у каждой базы свои правила работы с данными, поэтому быстро перейти от одной к другой не получится.
Какие свойства характерны для nosql решений
Содержание
Системы управления базами данных
NoSQL системы управления базами данных
В течение последнего десятилетия, выбор многих разработчиков и системных администраторов для их приложений всегда падал на реляционные СУБД. Не смотря на то, что они не такие уж и адаптивные, функционал реляционных СУБД позволяет создавать довольно сложные системы данных. Этого было более чем достаточно, пока не появились NoSQL СУБД.
По задумке NoSQL базы данных и СУБД не подразумевают внутренних связей. Они не основываются на одной модели, а каждая база данных в зависимости от целей использует различные модели.
Существует довольно много различных моделей и функциональных систем для NoSQL баз данных:
Чтобы лучше понять чем отличаются все эти типы СУБД, рассмотрим их.
Хранилище ключ-значение
Начнем наше рассмотрение с типа хранилища ключ-значение, так как это самое основное решение из семейства NoSQL. Этот тип БД работает с данными типа ключ-значение, например как словарь. Здесь нет места ни структуре, ни связям. После подключения к серверу (например Redis) приложение может задать ключ и его значение, а в последствии получать эти данныe по запросу.
Такие СУБД обычно используются для быстрого сохранения базовых данных, а иногда не таких уж и базовых, если подсчитать затраты процессора и памяти. Они, обычно, очень быстры, работоспособны или легко масштабируемы (хорошо использовать такие БД для хранения сессий, кеша, счётчиков посещений или просмотров и т.д.).
Заметка: когда дело касается компьютеров, словарь это особый тип данных. Он представляет собой массив коллекций с различными ключами и соответствующими им значениями.
Распределённое хранилище
По сути это следующий шаг после СУБД типа ключ-значение. Несмотря на довольно сложную для понимания сущность, эти базы данных отлично работают просто создавая коллекции из одного или нескольких пар ключ-значение, которые в сумме соответствуют одной записи.
В отличии от привычных таблиц в реляционных моделях, эти СУБД не требует предварительного описания структуры данных. Каждая запись состоит из одного или нескольких столбцов содержащих данные, а каждый столбец разных записей может хранить разные типы данных.
Документо-ориентированные хранилища
Такие NoSQL СУБД очень быстро захватили свой рынок. Они работают так же как и предыдущие системы, но они допускают гораздо большую вложенность и сложность структуры данных. (например, документ вложенный в документ, вложенный в документ). Документы снимают ограничения вложенности первого и второго уровней типа ключ-значение в распределённых хранилищах. В целом, можно описать сколь угодно сложную структуру данных как документ и сохранить в такой БД.
Несмотря на довольно большой функционал и способность доступа к данным по одному ключу, такие СУБД имеют ряд своих проблем. Например, при доступе к одному документу вы полностью получаете его в ответ на запрос, даже если вам необходимо какое-то одно поле, что не может не сказаться на производительности.
Базы данных на основе графов
На последок мы оставили самое интересное. БД на основе графов хранят данные в совсем другом виде. Они используют древовидные структуры с узлами и связями соединяющими их. Так же как и в математике, некоторые операции гораздо удобнее выполнять с такими данными благодаря связям между ними и их группировке (например, связи между людьми).
Такие базы данных часто используются в приложениях, где нужно иметь четко установленные связи. Например, когда вы регистрируетесь в какой либо социальной сети, хранить связи между вами и вашими друзьями хранить гораздо проще при использовании баз данных на основе графов.
СУБД Ключ-Значение (Key-Value)
Такие БД очень производительны, просты в обращении и легко масштабируются
Популярные СУБД
Некоторые популярные хранилища:
Примеры использования
Часто встречающиеся случаи применения БД хранилищ ключ-значение:
NoSQL распределённые СУБД
Такие системы баз данных очень эффективны и могут быть использованы для хранения важной информации больших объемов. Может они где то не очень гибки в плане данных, зато они функциональны и производительны.
Популярные СУБД
Вот основные представители этого типа БД:
Примеры использования
Основные области применения:
Документо-ориентированные СУБД
Документ-ориентированные хранилища отлично хранят несвязанную информацию больших объемов, даже если она очень разнится от сущности к сущности.
Популярные СУБД
Часто встречающиеся СУБД:
Примеры использования
Часто встречающиеся сферы применения:
NoSQL базы данных типа граф
Такие типы БД хранят информацию совершенно особенно, совсем не как все остальные СУБД.
Популярные СУБД
Часто встречаемые СУБД:
Примеры использования
Часто встречаемые примеры использования:
Сравнение NoSQL СУБД и реляционных СУБД
Чтобы иметь четкое представление чем NoSQL отличается от реляционных систем, давайте составим список с основными различиями.
Примеры использования NoSQL
NoSQL базы данных — преимущества и недостатки
Привет всем! В данной статье речь пойдёт про NoSQL базы данных, которые были спроектированы и созданы после массового внедрения реляционных баз данных.

Предпосылки появления
Ключевым фактором, заставившим мировое IT-сообщество задуматься над новыми стратегиями хранения и доступа к информации, стал планомерный рост объемов данных в сети Интернет. В связи с этим был создан термин Big Data, включающий в себя некую стратегию, позволяющую эффективно работать с огромными постоянно растущими массивами данных. И на фоне этой концепции четко вырисовывалась необходимость в модели базы данных, которая будет больше нацелена на скорость доступа и масштабируемость. Нужно было какое-то более простое решение, чем существующие реляционные БД, при этом не уступающее им в ряде конкретных задач. В первую очередь, это задачи построения облачных хранилищ, где конечному пользователю в первую очередь важна скорость доступа и возможный объем хранимой информации.
Виды NoSQL баз данных
Всего выделяют четыре основных типа NoSQL-хранилищ. Они различаются моделью данных, подходом к распределенности и репликации, благодаря чему могут в различной степени подходить под те или иные виды конкретных задач.
Хранилище вида “ключ-значение”
Хранилища “ключ-значение” представляют собой простейший вид базы данных, являясь, по сути, ассоциативным массивом — каждому значению сопоставляется свой уникальный ключ. Простота хранилищ этого типа открывает просторы невероятной масштабируемости. Не требуется никаких схем построения базы данных, нет никакой связи между значениями, по сути количество элементов ассоциативного массива ограничено лишь вычислительными мощностями. Именно потому данный вид хранилищ интересен в первую очередь компаниям, предоставляющим услуги облачного хостинга.
С другой стороны, простота хранилищ “ключ-значение” очень затрудняет или полностью отсекает большинство привычных операций со значениями хранилища — если ключами можно ещё оперировать как угодно, то попытка выполнить поиск по значениям может длиться на несколько порядков дольше, чем в реляционной базе данных. А вместе с ограниченным набором манипуляций над значениями ячеек хранилища идёт и фактическая невозможность быстро анализировать имеющуюся в базе данных информацию и собирать статистику.
Именно потому подобные хранилища используются в тех случаях, когда конкретное содержимое отдельной ячейки не интересно оператору базы данных — иначе говоря, полностью отсутствуют связи между отдельными ячейками хранилища. Базы данных типа “ключ-значение” не очень хорошо подходят в качестве полной замены реляционных БД, но нашли своё применение в качестве кэшей для объектов — ведь между кэшированными объектами разных пользователей точно так же нет связей, важна лишь скорость доступа к кэшу, а так же возможность быстро менять масштаб системы.
Наиболее известные примеры СУБД данного типа это Amazon DynamoDB, Berkeley DB, MemcacheDB, Redis и Riak.
Документоориентированные базы данных
Документоориентированная БД представляет собой систему хранения иерархических структур данных (документов), имеющую структуру дерева или леса. Структура дерева начинается с корневого узла и может иметь несколько внутренних и листовых узлов. Листовые узлы содержат конечные данные, которые при добавлении заносятся в индексы базы, благодаря которым можно осуществлять быстрый поиск даже при достаточно сложной общей структуре хранилища. Фактически документоориентированные БД являются более сложной версией хранилищ “ключ-значение” — они все ещё не очень хороши для систем, подразумевающих множество связей между элементами, но позволяют осуществлять выборку по запросу без полной загрузки отдельных документов в оперативную память. Механизмы поиска позволяют находить как документы целиком, так и части документов, а древовидная структура позволяет организовывать отдельные коллекции документов одного типа или схожей тематики.
К примеру, при создании музыкального хранилища можно создать коллекцию музыки 80х годов, в ней сделать отдельные коллекции по годам, а внутри них отдельные документы с треками выпущенных в этот год альбомов. Но если пользователь пожелает увидеть рейтинг самых популярных композиций определенного десятилетия — этот запрос будет выполняться достаточно долго, ведь придется просмотреть каждый документ всей базы данных. Таким образом, можно сделать вывод что документоориентированные БД найдут своё применение в задачах, где требуется упорядоченное хранение информации, но нет множества связей между данными и не нужно постоянно собирать статистику по ним. Документы не требуют определения схемы — это значит что каждый отдельный документ может состоять из любого количества уникальных полей — в отличие от реляционных баз данных, в которых при попытке хранить разнородные данные неизбежно появляются пустые поля.
Примеры СУБД данного типа: CouchDB, Couchbase, MarkLogic, MongoDB, eXist.
Графовые базы данных
Графовая модель базы данных представляет собой обобщение сетевой модели данных и отличается сильными связями между узлами.
Графовые базы данных лучше всего подходят для реализации проектов, предполагающих естественную графовую структуру данных — в первую очередь социальных сетей, а так же для создания семантических паутин. В подобных задачах они сильно опережают реляционные БД по производительности, простоте внесения изменений и наглядности представления информации. У некоторых баз данных существуют механизмы специальной оптимизации для работы с SSD-накопителями. Для работы с достаточно большими графами используются алгоритмы, предполагающие частичное помещение графа в оперативную память.
Наиболее известные графовые СУБД это ArangoDB, FlockDB, Giraph, HyperGraphDB, Neo4j, OrientDB.
Bigtable-подобные базы данных
Bigtable-подобные базы данных или иначе хранилища семейств колонок содержат данные, упорядоченные в виде разреженной матрицы, строки и столбцы которой используются в качестве ключей. Эти хранилища имеют много общего с документоориентированными БД — системы управления содержимым, регистрацию событий, блоги. Не стоит путать bigtable-подобные базы данных с колоночными хранилищами, которые являются, по сути, реляционными БД с раздельным хранением колонок.
Как правило, эти хранилища применяются для веб-индексирования и решения прочих задач, предполагающих огромные объемы данных.
Примерами СУБД данного типа являются: HBase, Cassandra, Hypertable, SimpleDB.
Сильные и слабые стороны NoSQL
Чтобы понять основную причину популярности NoSQL решений, а так же обозначить сферу их разумного применения стоит рассмотреть все предложенные варианты с нескольких сторон: выделить общие отличия всех NoSQL систем от реляционных БД, а так же обсудить те проекты, в которых NoSQL базы данных будут сильнее за счет конструктивных особенностей.
Отсутствие SQL
Первая особенность весьма очевидна — это отсутствие SQL (Structured Query Language) — универсального языка запросов, который используется всеми реляционными системами. Все NoSQL системы имеют собственный API для взаимодействия или встроенный язык запросов, зачастую являющийся просто урезанной версией SQL. Это решение имеет свои позитивные стороны:
Простота работы. Многие NoSQL решения, в основном хранилища вида “ключ-значение” имеют по сравнению с реляционными базами данных очень сильно урезанную функциональность, которая им просто не требуется для выполнения поставленных задач. В таком случае оператору базы данных не требуется глубоких знаний достаточно мощного и гибкого механизма работы с SQL-запросами. Это очень сильно снижает входной порог для начала работы с NoSQL хранилищами.
Более простой синтаксис запросов — меньше ошибок. Для упрощения работы с базой данных некоторыми разработчиками используется ORM (Object-Relational Mapping) — технология, позволяющая автоматически транслировать операции с объектами в запросы к базе данных. Зачастую подобные решения работают неэффективно и плодят множество ненужных или откровенно ошибочных запросов. Нельзя сказать, что разработчики ORM плохо выполняют свою работу — просто задача слишком сложна. Язык SQL универсален и очень емок, для полноценной работы с ним необходим определенный багаж знаний. При этом собственные языки запросов современных NoSQL хранилищ гораздо больше подходят для выполнения простых манипуляций с базой данных.
Недостатки у данного решения так же присутствуют, притом в долгосрочной перспективе они могут серьёзно перевесить все позитивные моменты:
Простота и молодость NoSQL
Если преимущества простоты NoSQL хранилищ достаточно очевидны, то недостатки зачастую выясняются только с горьким опытом. Во-первых, ограничения структуры реляционных БД в определенной степени гарантируют целостность данных — информация, которая не удовлетворяет ограничениям по типу, просто не сможет попасть в базу. В случае использования, например, хранилищ типа “ключ-значение” задача контроля целостности данных полностью ложится на приложение. Во-вторых, процесс создания реляционного хранилища включает в себя этап проектирования модели данных. На этой стадии можно оценить узкие места выбранной стратегии и спроектировать действительно надёжную и удобную систему. NoSQL решения не требуют определять схему базы данных перед началом работы. Но без этапа первоначального тестирования и планирования можно в процессе разработки наткнуться на непредвиденные трудности, которые могут даже полностью отсечь вариант работы с конкретным NoSQL решением. А учитывая описанные в предыдущем пункты трудности быстрого перехода с одной нереляционной базы данных на другую — цена ошибки становится очень высокой.
Теперь есть смысл обсудить другую важную особенность NoSQL решений — они все по большей части весьма молоды. Многие из них распространяются по BSD-подобной лицензии и поддерживаются усилиями сообщества. У каждой компании свои требования к надежности базы данных, и большая часть NoSQL решений остаются незамеченными зачастую, потому что они являются ещё слишком молодыми решениями. Многие нереляционные хранилища существуют лишь в виде бета-версий, и даже самые зрелые имеют достаточно малый багаж историй успешного внедрения по сравнению с реляционными СУБД. Помимо вероятности наличия багов и уязвимостей в самом коде нереляционных СУБД, это приводит к другим ошибкам — некоторые компании выбирают решения, которые просто не соответствуют их нуждам.
Самые сильные стороны NoSQL
После обзора спорных особенностей большинства NoSQL решений есть смысл рассмотреть то направление, в котором эти системы максимально раскрывают свой потенциал. Это распределённые системы. Весомыми преимуществами при работе с распределенными системами обладают все типы нереляционных хранилищ, за исключением графовых БД — они по определению предполагают большое количество связей между узлами данных.
Лавинообразный рост количества данных в мировой сети обострил проблему вертикальной масштабируемости — вычислительные мощности железа могут расти не бесконечно, да и цена нескольких простых серверов меньше, чем одного высокопроизводительного. В такой ситуации хорошим выходом станет горизонтальное масштабирование, когда несколько независимых машин соединяются вместе и каждая из них обрабатывает только часть запросов. Такая архитектура делает возможным быстрое увеличение мощности кластера путем добавления нового сервера. Рассчитанные на работу в распределенных системах NoSQL хранилища изначально проектируются с таким расчетом, что все процедуры репликации, распределения данных и обеспечения отказоустойчивости выполняются самой NoSQL базой.
Ключевые преимущества NoSQL баз в распределенных системах заключаются в процедурах шаринга и репликации.
Репликация — это копирование данных при их обновлении на другие сервера. Этот механизм позволяет добиться большей отказоустойчивости и масштабируемости системы. Принято выделять два вида репликации: master-slave и peer-to-peer.
Первый тип подразумевает наличие одного мастер-сервера и нескольких дочерних серверов. Запись может производиться только на мастер-сервер, а он в свою очередь передаёт изменения на дочерние машины. Этот тип репликации даёт хорошую масштабируемость на чтение(чтение может происходить с любого узла сети), но не позволяет масштабировать операции записи — запись идёт только на один мастер-сервер. Так же такой вариант организации репликации предполагает сложности в случае неисправности мастер-сервера — в таком случае должен происходить автоматический или ручной выбор нового мастер-сервера из оставшихся.
Второй тип — peer-to-peer — предполагает, что все узлы равны в возможности обслуживать запросы на чтение и запись. Информация о обновлении данных передаётся от сервера к серверу по кругу.
Шаринг — это разделение массива информации по разным узлам сети — когда каждый узел отвечает только за определенный набор данных и обрабатывает запросы на чтение и запись, относящиеся только к этому набору данных. Эта технология использовалась при работе с реляционными базами данных в достаточно сыром виде — на уровне приложения создавались независимые базы данных, по которым распределялись запросы пользователей. Концепция NoSQL предполагает, что ответственность за этот механизм будет лежать на базе данных, и шаринг будет производиться автоматически.
Социальные данные
Достаточно популярным аргументом на стороне решений является тот факт, что социальные данные не являются реляционными и реализация крупных социальных сетей средствами SQL хранилищ связана с определенными сложностями. Действительно, формирование ленты новостей для пользователя средствами реляционной базы данных представляет собой операцию соединения нескольких таблиц. Посты новостной ленты, лайки и комментарии, аватары пользователей и множество других данных, необходимых для формирования новостной ленты обычно хранятся раздельно, поэтому сведение этих данных воедино зачастую проходит не так быстро, как хотелось бы. Сохранение всей ленты пользователя в виде единой ненормализованной структуры выглядит очень хорошим решением. Но реализованные в данный момент графовые NoSQL базы имеют проблему с масштабированием, что не позволяет использовать их для крупных социальных сетей. Помимо этого реляционные хранилища обладают и рядом других преимуществ, в числе которых надежность, гарантия целостности информации и безопасности пользовательских данных. При реализации действительно сложных многопользовательских проектов молниеносная скорость и бесконечная масштабируемость системы редко выходят на первый план — в первую очередь компании стремятся сделать надежный продукт.
Пик популярности NoSQL решений был во многом связан с амбициозным заявлением, поступившим от социальной сети Twitter. Они видели определенные недостатки работы с реляционным хранилищем MySQL для своих твитов и изъявили желание перейти на новую NoSQL СУБД Cassandra. Но эта идея так и не была воплощена в жизни — как комментируют этот момент сами сотрудники Twitter — компания оценила свои приоритеты, после чего решение было признано слишком рискованным. С другой стороны, то же самое NoSQL хранилище отлично прижилось в качестве основной базы данных для социальных сетей Instagram и Facebook — а это уже очень весомые истории успеха для всего семейства NoSQL.
Аналитика данных
В облачных хранилищах и разработанных для них NoSQL решениях часто используется принцип множественной аренды. Он заключается в том, что большое количество пользователей одновременно использует одну и ту же систему. Чтобы предотвратить её перегруз в решениях, рассчитанных на большую масштабируемость, применяют политику ограничения запросов. Например, в SimpleDB время выполнение запроса не может превышать 5 секунд, а в Google AppEngine Datastore один запрос к базе не позволяет получить более 1000 записей.
Эти ограничения не страшны для простой работы приложения, но значительно сказываются на возможностях аналитики данных. Компании часто извлекают выгоду из больших объемов пользовательских данных — на основе их анализа можно выделять наиболее популярные продукты, составлять “на лету” списки рекомендаций для конкретных групп пользователей основываясь на их личных данных или истории. Для многих NoSQL решений подобные функции сложно реализуемы или попросту невозможны.
Интересным вариантом для решения этой проблемы становится создание отдельного хранилища, куда данные периодически дублируются для анализа. Конечно, перенос миллионов записей частями по 1000 штук за запрос может сильно затянуться, так что этот момент стоит продумать заранее.
Выводы
Резкий скачок популярности NoSQL баз данных и связанные с ним истории использования нереляционных СУБД показали миру IT важность реалистичной оценки приоритетов компании. Некоторые вендоры успешно внедрили у себя NoSQL хранилища и получили заметное снижение убытков и повышение качества приложений. Другие потерпели неудачу, поздно поняв, что принятое решение им не подходит. А третьи просто остались со своими технологиями. Реляционные или нереляционные базы данных — это не единственный выбор, который предстоит сделать компании. Не менее важен и выбор между конкретными системами и конкретными стратегиями работы с ними.
В любом случае, NoSQL-революции не произошло — реляционные базы данных удерживают стабильно доминирующие позиции. Они являют собой симбиоз надежности, функциональности и универсальности. При этом многие NoSQL решения направлены на закрытие совершенно конкретных проблем SQL хранилищ — в первую очередь на усиление горизонтальной масштабируемости. Многие нереляционные базы данных отлично работают, выполняя цель своего создания, но при этом они уже не являются тем универсальным продуктом, которым являются SQL. У большинства компаний просто нет таких объемов данных и других специфических условий работы, в которых NoSQL решения являлись бы панацеей или просто были бы выгодны в качестве основной базы данных. NoSQL хранилища показывают себя с очень хорошей стороны в симбиозе с реляционными базами данных. Например, в системах, где основной объем информации хранит SQL, а за кэш отвечает NoSQL. Для захвата более существенных позиций на рынке нереляционным системам всё ещё не хватает множества базовых вещей — универсальности, надежности, целостности и предсказуемости.


