Шпаргалка по регулярным выражениям. В примерах

Jan 6, 2019 · 5 min read
Регулярные выражения (regex или regexp) очень эффективны для извлечения информации из текста. Для этого нужно произвести поиск одного или нескольких совпадений по определённому шаблону (т. е. определённой последовательности символов ASCII или unicode).
Области применения regex разнообразны, от валидации до парсинга/замены строк, передачи данных в другие форматы и Web Scraping’а.
Одна из любопытных особенностей регулярных выражени й в их универсальности, стоит вам выучить синтаксис, и вы сможете применять их в любом (почти) языке программирования (JavaScript, Java, VB, C #, C / C++, Python, Perl, Ruby, Delphi, R, Tcl, и многих других). Небольшие отличия касаются только наиболее продвинутых функций и версий синтаксиса, поддерживаемых движком.
Давайте начнём с нескольких примеров.
Основы
Оператор ИЛИ — | или []
Флаги
Мы научились строить регулярные выражения, но забыли о фундаментальной концепции ― флагах.
Средний уровень
Скобочные группы ― ()
Этот оператор очень полезен, когда нужно извлечь информацию из строк или данных, используя ваш любимый язык программирования. Любые множественные совпадения, по нескольким группам, будут представлены в виде классического массива: доступ к их значениям можно получить с помощью индекса из результатов сопоставления.
Скобочные выражения ― []
Помните, что внутри скобочных выражений все специальные символы (включая обратную косую черту \ ) теряют своё служебное значение, поэтому нам ненужно их экранировать.
Жадные и ленивые сопоставления
Квантификаторы ( * + <> ) ― это «жадные» операторы, потому что они продолжают поиск соответствий, как можно глубже ― через весь текст.
Например, выражение соответствует
Продвинутый уровень
Границы слов ― \b и \B
6 пунктов, которые помогут легко разобраться с regexp
Давно хотели изучить regexp? Это небольшое руководство поможет разобраться с ними в 6 этапов, а обилие примеров позволит закрепить материал.
Что такое regexp?
Regexp представляет собой группу символов или знаков, которая используется для поиска определенного текстового шаблона.
Регулярное выражение – это шаблон, который сравнивается с предметной строкой слева направо. Словосочетание “regular expression” применяется не так широко, вместо него обычно употребляют “regex” и “regexp”. Регулярное выражение используется для замены текста внутри строки, проверки формы, извлечения подстроки из строки на основе соответствия шаблона и т. д.
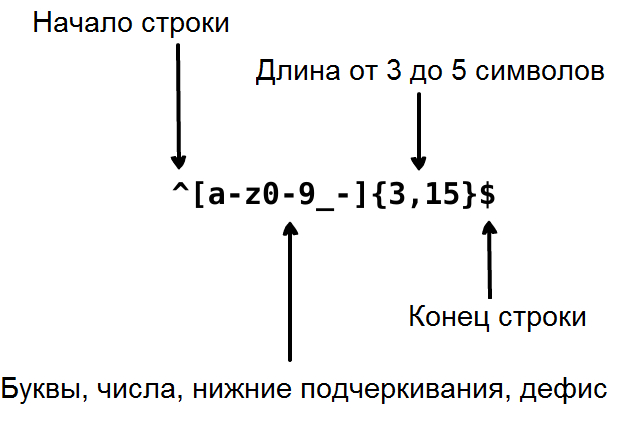
Предположим, вы создаете приложение и хотите определить правила, согласно которым пользователи будут выбирать себе имя. Например, мы хотим, чтобы оно содержало буквы, цифры, нижнее подчеркивание и дефисы. Также нам бы хотелось ограничить количество символов в имени пользователя, чтобы оно не выглядело уродливым. Поэтому для проверки будем использовать следующее регулярное выражение:
1. Базовые совпадения
«the» => The fat cat sat on the mat.
«The» => The fat cat sat on the mat.
2. Метасимволы
Метасимволы служат строительными блоками regexp. Они не являются независимыми и обычно интерпретируются каким-либо образом. Некоторые метасимволы имеют особое значение, а потому помещаются в квадратные скобки. Метасимволы:
2.1 Точка
«.ar» => The car parked in the garage.
2.2 Интервал символов
«[Tt]he » => The car parked in the garage.
«ar [.]» => A garage is a good place to park a car.
2.2.1 Отрицание набора символов
«[^c]ar» => The car parked in the garage.
2.3 Повторения
2.3.1 Звездочка
Этот символ поможет найти одно или более копий какого-либо символа. Регулярное выражение a* означает 0 или более повторений символа a. Но если этот символ появится после набора или класса символов, тогда будут найдены повторения всего сета. Например, выражение [a-z]* означает любое количество этих символов в строке.
«[a-z]*» => The car parked in the garage #21.
«\s*cat\s*» => The fat cat sat on the concatenation.
2.3.2 Плюс
«c.+t» => The fat cat sat on the mat.
2.3.3. Вопросительный знак
«[T]?he» => The car is parked in the garage.
2.4 Скобки
Скобки в regexp, которые также называются квантификаторами, используются для указания допустимого количества повторов символа или группы символов. Например, регулярное выражение 1 <2,3>означает, что допустимое количество цифр должно быть не менее двух цифр, но не более 3 (символы в диапазоне от 0 до 9).
«2<2,3>» => The number was 9.9997 but we rounded it off to 10.0.
Мы можем убрать второе число. Например, выражение 7 <2,>означает 2 или более цифр. Если мы также уберем запятую, то тогда выражение 4 <3>будет находить только лишь 3 цифры, ни меньше и ни больше.
«7<2,>» => The number was 9.9997 but we rounded it off to 10.0.
«6<3>» => The number was 9.9997 but rounded it off to 10.0.
2.5 Символьная группа
«(c|g|p)ar» => The car is parked in the garage.
2.6 Перечисление
«(T|t)he|car» => The car is parked in the garage.
2.7 Исключение специального символа
«(f|c|m)at\.?» => The fat cat sat on the mat.
2.8.1. Caret
«(T|t)he» => The car is parked in the garage.
«^(T|t)he» => The car is parked in the garage.
2.8.2 Доллар
«(at\.)» => The fat cat. sat. on the mat.
«(at\.)$» => The fat cat. sat. on the mat.
Тестировать выражение
3. Сокращения для обозначения символов
Regexp позволяет использовать сокращения для некоторых наборов символов, что делает работу с ними более комфортной. Таким образом, здесь используются следующие сокращения:
| Сокращение | Описание |
|---|---|
| . | Любой символ, кроме новой строки |
| \w | Соответствует буквенно-цифровым символам: [a-zA-Z0-9_] |
| \W | Соответствует не буквенно-цифровым символам: [^\w] |
| \d | Соответствует цифрам: 1 |
| \D | Соответствует нецифровым знакам: [^\d] |
| \s | Соответствует знаку пробела: [\t\n\f\r\p |
| \S | Соответствует символам без пробела: [^\s] |
4. Lookaround Позиционная проверка
«(T|t)he(?=\sfat)» => The fat cat sat on the mat.
4.2 Отрицательный Lookahead
«(T|t)he(?!\sfat)» => The fat cat sat on the mat.
4.3 Положительный Lookbehind
«(? The fat cat sat on the mat.
4.4 Отрицательный Lookbehind
«(? The cat sat on cat.
5. Флаги
Флаги также часто называют модификаторами, так как они могут изменять вывод regexp. Флаги, приведенные ниже являются неотъемлемой частью и могут быть использованы в любом порядке или сочетании regexp.
| Флаг | Описание |
|---|---|
| i | Нечувствительность к регистру: делает выражение нечувствительным к регистру. |
| g | Глобальный поиск: поиск шаблона во всей строке ввода. |
| m | Многострочность: анкер метасимвола работает в каждой строке. |
5.1 Нечувствительные к регистру
«/The/gi» => The fat cat sat on the mat.
5.2 Глобальный поиск
«/.(at)/» => The fat cat sat on the mat.
«/.(at)/g» => The fat cat sat on the mat.
5.3 Многострочный поиск
«/.at(.)?$/» => The fat
cat sat
on the mat.
«/.at(.)?$/gm» => The fat
cat sat
on the mat.
6. Жадные vs. ленивые выражения
По умолчанию регулярные выражения выполняются благодаря «жадным» квантификаторам, им соответсвует максимально длинная строка из всех возможных.
«/(.*at)/» => The fat cat sat on the mat.
«/(.*?at)/» => The fat cat sat on the mat.
Регулярные выражения, пособие для новичков. Часть 1
Регулярные выражения (РВ) это, по существу, крошечный язык программирования, встроенный в Python и доступный при помощи модуля re. Используя его, вы указывается правила для множества возможных строк, которые вы хотите проверить; это множество может содержать английские фразы, или адреса электронной почты, или TeX команды, или все что угодно. С помощью РВ вы можете задавать вопросы, такие как «Соответствует ли эта строка шаблону?», или «Совпадает ли шаблон где-нибудь с этой строкой?». Вы можете также использовать регулярные выражения, чтобы изменить строку или разбить ее на части различными способами.
Шаблоны регулярных выражений компилируются в серии байт-кода, которые затем исполняются соответствующим движком написанным на C. Для продвинутого использования может быть важно уделять внимание тому, как движок будет выполнять данное регулярное выражение, и писать его так, чтобы получался байт-код, который работает быстрее. Оптимизация не рассматривается в этом документе, так как она требует от вас хорошего понимания внутренних деталей движка.
Язык регулярных выражений относительно мал и ограничен, поэтому не все возможные задачи по обработке строк можно сделать с помощью регулярных выражений. Также существуют задачи, которые можно сделать с помощью регулярных выражений, но выражения оказываются слишком сложными. В этих случаях может быть лучше написать обычный Python код, пусть он будет работать медленнее, чем разработанное регулярное выражение, но будет более понятен.
Простые шаблоны
Мы начнем с изучения простейших регулярных выражений. Поскольку регулярные выражения используются для работы со строками, мы начнем с наиболее распространенной задачи — соответствия символов.
За подробным объяснением технической стороны регулярных выражений (детерминированных и недетерминированных конечных автоматов) вы можете обратиться к практически любому учебнику по написанию компиляторов.
Соответствие символов
Из этого правила есть исключения; некоторые символы это специальные метасимволы, и сами себе не соответствуют. Вместо этого они указывают, что должна быть найдена некоторая необычная вещь, или влияют на другие части регулярного выражения, повторяя или изменяя их значение. Большая часть этого пособия посвящена обсуждению различных метасимволов и тому, что они делают.
Вот полный список метасимволов; их значения будут обсуждаться в остальной части этого HOWTO.
Некоторые из специальных последовательностей, начинающихся с ‘\’ представляют предопределенные наборы символов, часто бывающие полезными, такие как набор цифр, набор букв, или множества всего, что не является пробелами, символами табуляции и т. д. (whitespace). Следующие предопределенные последовательности являются их подмножеством. Полный список последовательностей и расширенных определений классов для Юникод-строк смотрите в последней части Regular Expression Syntax.
Эти последовательности могут быть включены в класс символов. Например, [\s,.] является характер класс, который будет соответствовать любому whitespace-символу или запятой или точке.
Повторяющиеся вещи
Возможность сопоставлять различные наборы символов это первое, что регулярные выражения могут сделать и что не всегда можно сделать строковыми методами. Однако, если бы это было единственной дополнительной возможностью, они бы не были так интересны. Другая возможность заключается в том, что вы можете указать какое число раз должна повторяться часть регулярного выражения.
Например, ca*t будет соответствовать ct (0 символов a ), cat (1 символ a ), caaat (3 символа a ), и так далее. Движок регулярных выражений имеет различные внутренние ограничения вытекающие из размера int типа для C, что не позволяет проводить ему сопоставление более 2 миллиардов символов ‘a’. (Надеюсь, вам это не понадобится).
Повторения, такие как * называют жадными (greedy); движок будет пытаться повторить его столько раз, сколько это возможно. Если следующие части шаблона не соответствуют, движок вернется назад и попытается попробовать снова с несколькими повторами символа.
Использование регулярных выражений
Теперь, когда мы рассмотрели несколько простых регулярных выражений, как мы можем использовать их в Python? Модуль re предоставляет интерфейс для регулярных выражений, что позволяет компилировать регулярные выражения в объекты, а затем выполнять с ними сопоставления.
Компиляция регулярных выражений
Регулярные выражения компилируются в объекты шаблонов, имеющие методы для различных операций, таких как поиск вхождения шаблона или выполнение замены строки.
re.compile() также принимает необязательные аргументы, использующихся для включения различных особенностей и вариаций синтаксиса:
>>> p = re.compile(‘ab*’, re.IGNORECASE)
Передача регулярных выражений в виде строки позволяет Python быть проще, но имеет один недостаток, который является темой следующего раздела.
Бэкслеш бедствие
(Или обратная косая чума 🙂 )
Как было отмечено ранее, в регулярных выражениях для того, чтобы обозначить специальную форму или позволить символам потерять их особую роль, используется символ бэкслеша ( ‘\’ ). Это приводит к конфликту с использованием в строковых литералах Python такого же символа с той же целью.
Решение заключается в использовании для регулярных выражений «сырых» строк (raw string); в строковых литералах с префиксом ‘r’ слэши никак не обрабатываются, так что r»\n» это строка из двух символов (‘\’ и ‘n’), а «\n» — из одного символа новой строки. Поэтому регулярные выражения часто будут записываться с использованием сырых строк.
| Regular String | Raw string |
| ‘ab*’ | r’ab*’ |
| ‘\\\\section’ | r’\\section*’ |
| ‘\\w+\\s+\\1’ | r’\w+\s+\1′ |
Выполнение сопоставлений
| Метод/атрибут | Цель |
| match() | Определить, начинается ли совпадение регулярного выражения с начала строки |
| search() | Сканировать всю строку в поисках всех мест совпадений с регулярным выражением |
| findall() | Найти все подстроки совпадений с регулярным выражением и вернуть их в виде списка |
| finditer() | Найти все подстроки совпадений с регулярным выражением и вернуть их в виде итератора |
В этом пособии мы используем для примеров стандартный интерпретатор Python:
>>> m = p. match ( ‘tempo’ )
>>> print m
_sre. SRE_Match object at 0x. >
Теперь вы можете вызывать MatchObject для получения информации о соответствующих строках. Для MatchObject также имеется несколько методов и атрибутов, наиболее важными из которых являются:
| Метод/атрибут | Цель |
| group() | Вернуть строку, сошедшуюся с регулярным выражением |
| start() | Вернуть позицию начала совпадения |
| end() | Вернуть позицию конца совпадения |
| span() | Вернуть кортеж (start, end) позиций совпадения |
Так как метод match() проверяет совпадения только с начала строки, start() всегда будет возвращать 0. Однако метод search() сканирует всю строку, так что для него начало не обязательно в нуле:
Два метода возвращают все совпадения для шаблона. findall() возвращает список совпавших подстрок:
Метод findall() должен создать полный список, прежде чем он может быть возвращен в качестве результата. Метод finditer() возвращает последовательность экземпляров MatchObject в качестве итератора.
Функции на уровне модуля
Эти функции просто создают для вас объект шаблона и вызывают соответствующий метод. Они также хранят объект в кэше, так что будущие вызовы с использованием того же регулярного выражения будут быстрее.
Должны вы использовать эти функции или шаблоны с методами? Это зависит от того, как часто будет использоваться регулярное выражение и от вашего личного стиля кодинга. Если регулярное выражение используется только в одном месте кода, то такие функции, вероятно, более удобны. Если программа содержит много регулярных выражений, или повторно использует одни и те же в нескольких местах, то будет целесообразно собрать все определения в одном месте, в разделе кода, который предварительно компилирует все регулярные выражения. В качестве примера из стандартной библиотеки, вот кусок из xmllib.py :
Сам я предпочитаю работать со скомпилированными объектами, даже для одноразового использования, но мало кто окажется таким же пуристом в этом, как я.
Флаги компиляции
IGNORECASE, I
Сопоставление без учета регистра; Например, [A-Z] будет также соответствовать и строчным буквам, так что Spam будет соответствовать Spam, spam, spAM и так далее.
LOCALE, L
Делает \w, \W, \b, \B зависящими от локализации. Например, если вы работаете с текстом на французском, и хотите написать \w+ для того, чтобы находить слова, но \w ищет только символы из множества [A-Za-z] и не будет искать ‘é’ или ‘ç’. Если система настроена правильно и выбран французский язык, ‘é’ также будет рассматриваться как буква.
UNICODE, U
Делает \w, \W, \b, \B, \d, \D, \s, \S соответствующими таблице Unicode.
Пример того, как РВ становится существенно проще читать:
Без verbose это выглядело бы так:
На этом месте мы пока завершим наше рассмотрение. Советую немного отдохнуть перед второй половиной, содержащей рассказ о других метасимволах, методах разбиения, поиска и замены строк и большое количество примеров использования регулярных выражений.
Регулярные выражения. Всё проще, чем кажется
Всем доброго времени суток. Сегодня хочу рассказать максимум о регулярных выражениях: что они из себя представляют, как их писать, для чего нужны и т.д.
Информации о регулярках много, они разбросаны по разным сайтам и я решил собрать всё, касательно регулярок, в одну статью. Ну что-ж, приступим поскорее к делу 🙂
Содержание
Что такое регулярка и с чем ее едят?
Где писать регулярки?
Самые простые регулярки
Специальные символы квантификаторов
Lookahead и lookbehind (опережающая и ретроспективная проверки)
Регулярные выражения в разных языках программирования
Что такое регулярка и с чем ее едят?
Если по простому, регулярка- это некий шаблон, по которому фильтруется текст. Мы можем написать нужный нам шаблон (регулярку) и таким образом искать в тексте необходимые нам символы, слова и т.д. Также их используют, например, при заполнении поля E-mail на различных сайтах, т.е. создают шаблон по типу: someEmail@gmail.com. Это я взял как пример, не более. Теперь, разобравшись, что это, приступим к изучению. Обещаю, скучно не будет)
Где писать регулярки?
Регулярки мы можем писать как на специальных сайтах, так и используя какой-либо язык программирования. Синтаксис (правила написания регулярок) не привязан к какому-то отдельному языку программирования. Поэтому, изучив регулярные выражения, вы сможете пользоваться ими где захотите. Сначала, в рамках изучения, воспользуемся отличным сайтом, а как писать регулярные выражения в различных языках программирования, рассмотрим чуточку позже.
Сразу дам ссылку на сайт, чтобы вы могли уже писать вместе со мной https://www.regextester.com/
Коротко о том, как пользоваться сайтом. Сверху, в графе Regular Expression вы пишете само регулярное выражение, а под ним, в графе Test String вы пишете строку, которую вы хотите фильтровать. Если были найдены соответствия между регулярным выражением и текстом, в тексте эти соответствия будут помечены синим цветом, вы их сразу увидите, даже не сомневайтесь.
Самые простые регулярки
Перед тем, как писать регулярку, возьмем некоторый текст, чтобы мы не фильтровали пустоту. Допустим, у нас будет строка some text. И допустим мы хотим найти слово text. Для этого в саму регулярку мы должны написать просто слово text и он найдет его.
 Пример регулярки
Пример регулярки
Вот и всё, надеюсь вы поняли регулярные выражения, спасибо за внимание.
Шутка конечно, это далеко не всё. Например, мы можем написать одну букву t, и он найдет все буквы t в тексте.
Таким образом вы можете просто указывать какие-то символы, но нам не всегда даются конкретные символы, а нужно написать какой-то шаблон. Сейчас этим и займемся.
Квантификаторы
Понимаю, звучит страшно, но на деле все просто. Сейчас разберемся.
С помощью квантификаторов мы можем указывать сколько раз должен повторяться тот или иной символ (ну или группа символов). Ниже приведу список квантификаторов с пояснением, а дальше попрактикуемся с ними.
— символ повторяется ровно n раз
— символ повторяется в диапазоне от m до n раз
— символ повторяется минимум m раз (от m и более)
Почему же он взял еще ssss? Он взял не совсем его, а лишь его часть, так как в нем тоже есть 3 буквы s подряд. Дело в том, что регулярка не будет учитывать, отдельное это слово или нет. Пробелы тоже идут как символы! Поэтому будет выбран любой фрагмент, которому соответствует 3 идущие подряд буквы s
Интересный момент получается, он выбрал все. Почему же? Ответ: та же ситуация, что и в прошлый раз. Он увидел ssss, взял 3 идущие подряд s вместе и еще одну s, которая рядом, ведь она тоже соответствует регулярку (а ведь мы помним, что мы указали диапазон от одного до трех раз)
Ну и напоследок, давайте напишем шаблон, где символ s будет повторяться минимум три раза. Для этого напишем следующее: s ( <3,>обозначает, что символ s будет повторяться от трех раз и до бесконечности).
Специальные символы квантификаторов
Есть уже готовые квантификаторы, которые обозначаются спец. символами. Вот они:
Давайте разбираться. Начнем со знака вопроса. Допустим у нас есть строка colour color и мы хотим найти либо colour, либо color. Мы можем написать так: colou?r.
Давайте изменим строку и напишем что-то по типу colouuuuur color. И допустим мы хотим указать, что u должен либо не быть, либо быть сколько угодно раз. Для этого мы можем написать colou*r.
То есть либо u у нас нет, либо повторяется много раз.
Символ + работает почти также, за исключением того, что символ должен повторяться минимум 1 раз. То есть в данном случае слово color не будет соответствовать, так как там u не присутствует (то есть повторяется 0 раз, а у нас символ должен повторяться минимум 1 раз)
Специальные символы
Теперь поговорим о специальных символах, которые используются в регулярках. Тут все очень просто, так что можете сильно не переживать. Скрины прикреплять буду здесь не везде (тогда статья разрастется до безумных размеров). Так что заранее прошу меня понять и простить и попробовать сами.
Поговорим об одиночном символе. Это значит, что будет выбираться любой символ, который повторяется только один раз. Например, вернемся к нашей строке Some text и выберем букву t, после которой идет любой символ. Для этого напишем t.
Выберется te, так как после t идет один любой символ (в данном случае е)
Теперь давайте возьмем слово test и выделим в нем первую букву t. Для этого мы можем написать ^t. То есть мы написали символ t и указали, что он должен находиться в самом начале строки. Важно поставить символ ^ перед нужным нам символом.
Теперь давайте сделаем наоборот и возьмем последнюю букву t. Для этого напишем t$. Важно, чтобы символ $ стоял после нужного нам символа.
Перейдем к экранированию. Звучит страшно, но на деле все проще простого. Например, в тексте some text. мы хотим выделить точку. Но ведь точка у нас уже зарезервирована как специальный символ (напоминаю, точка обозначает любой одиночный символ). И чтобы сделать так, чтобы точка на считалась как спец. символ мы можем написать \. и тем самым говоря, что точка у нас будет как обычный символ.
Теперь идут, простые вещи. \d у нас обозначает любую цифру. Например в тексте some text123, если написать \d у нас будут выделяться только цифры.
\D делает все наоборот: берутся все символы, кроме цифр. То есть, если написать \D будет браться все, кроме цифр (и пробелы, кстати, тоже).
\w берет буквы, а \W берет, все, кроме букв (в том числе и пробелы).
Теперь расскажу про еще одно применение символа ^. Его можно использовать как отрицание, тем самым исключая символ или группу символов. Например, в слове test мы хотим выбрать все, кроме буквы t и для этого мы можем написать так: [^t]
Именно в такой последовательности символ ^ будет обозначать отрицание.
Lookahead и lookbehind (опережающая и ретроспективная проверки)
Давайте разберемся, что это такое. Lookahead или же опережающая проверка позволяет выбрать символ или группу символов, если после него идет идет какой-либо символ или группа символов. Lookbehind или же ретроспективная проверка позволяет выбрать символ или группу символов, если до них идет какой-то символ или группа символов.
Также мы можем сделать наоборот и выбрать символ s, если после него НЕ идет символ d. Для этого вместо знака равно мы должны поставить восклицательный знак (!), т.е. написать вот так: s(?!d)
Теперь поговорим о lookbehind. Допустим, у нас есть строка s ws ds ts es и мы хотим выбрать символ s, до которого будет символ d. Для этого мы можем написать так: (?
Почему же lookbehind подчеркивается красной линией? Дело в том, что lookbehind не всегда поддерживается и не везде такая регулярка будет работать. Нужно искать способ заменить этот lookbehind, но это зависит от поставленной задачи, поэтому нельзя сказать, как именно ее заменять. Будем надеяться, что в скором временем будет полная поддержка этой возможности.
Чтобы сделать наоборот, то есть выбрать все символы s, до которых НЕ будет идти символ d, нужно опять же поменять знак равно на восклицательный знак: (?
Регулярные выражения в разных языках программирования
Здесь я приведу примеры использования регулярных выражений в различных языках программирования. Заранее говорю, я не буду заострять внимание на синтаксисе языка программирования, так как это уже не касается данной темы
Здесь мы создаем строку с текстом, который хотим проверить, создаем объект класса Regex и в конструктор пишем нашу регулярку (как я и говорил, я не буду заострять внимание на том, что такое объект класса и конструктор). Потом создаем объект класса MatchCollection и от объекта regex вызываем метод Matches и в параметры передаем нашу строку. В результате все сопоставления будут добавляться в коллекцию matches.
Java
Здесь похожая ситуация. Создаем объект класса Pattern и записываем нашу строку. CASE_INSENSITIVE означает, что он не привязан к регистру (то есть нет разницы между заглавными и строчными символами). Создаем объект класса Matcher и пишем туда регулярку.
JavaScript
Здесь тоже все просто. Вы создаете объект regex и пишете туда регулярку. И затем просто создаете объект matches, который будет являться коллекцией и вызываете метод exec и в параметры передаете строку.
Заключение
Итак, мы разобрали, что такое регулярные выражения, где они используются, как их писать и использовать в контексте языков программирования. Скажу сразу, написание регулярок приходит с опытом. Практикуйтесь, и я уверен: все у вас получится! А на этом я с вами прощаюсь. Спасибо за внимание и приятного всем дня)


